
Stop met dashboards die niemand opent
Conversational BI
Je bedrijf heeft meer vragen dan dashboards. Met conversational BI krijg je eindelijk antwoorden.
Wat is conversational BI?
Conversational BI (ook wel conversational analytics, generative BI of GenBI genoemd) laat mensen vragen stellen over hun business in gewone mensentaal, en geeft daar in seconden een antwoord op met data erachter. Geen SQL. Geen ticket naar het BI-team. Geen week wachten tot iemand alweer een nieuw dashboard bouwt.
Als je al eens met ChatGPT, Claude of Power BI Copilot gewerkt hebt, ken je de interactie. Stel een vraag. Krijg een antwoord. Stel een vervolgvraag. Zoom in. Het verschil: achter die chat zit jouw bedrijfsdata, jouw definities, jouw cijfers.
Power BI Copilot. Tableau Pulse. ThoughtSpot Spotter. Looker Conversational Analytics. Databricks Genie. Qlik Answers. Elke grote BI-vendor rolt deze laag nu uit. De categorie is reëel, en ze beweegt snel.
Het vervangt je dashboards niet. Het vervangt de slechte dashboards.
Een goed dashboard vertelt elke maandagochtend hetzelfde verhaal. Marge. OTIF. Service level. Voorraaddagen. Conversie. De KPI's waarop je stuurt. Die blijven staan waar ze staan: zichtbaar, consistent, governed.
Wat conversational BI vervangt, is de lange staart van eenmalige dashboards. Het dashboard voor één boardvergadering. Het Excel-bestand dat iemand elk kwartaal opnieuw bouwt omdat het bestaande dashboard de vraag niet helemaal beantwoordt. De "kun je me een rapportje trekken" mails die de inbox van je analist opvullen.
In de meeste bedrijven worden 80% van de dashboards door minder dan vijf mensen gebruikt. De helft wordt twee keer geopend en daarna nooit meer. Dat is de lange staart die conversational BI opvreet.
| Use case | Beste oplossing |
|---|---|
| Maandelijkse boardrapportering | Klassiek dashboard |
| Dagelijks ops-overzicht (OTIF, voorraad, service level) | Klassiek dashboard |
| Kwartaalafsluiting | Klassiek dashboard / rapport |
| Audit- en regelgevingsrapportering | Klassiek dashboard |
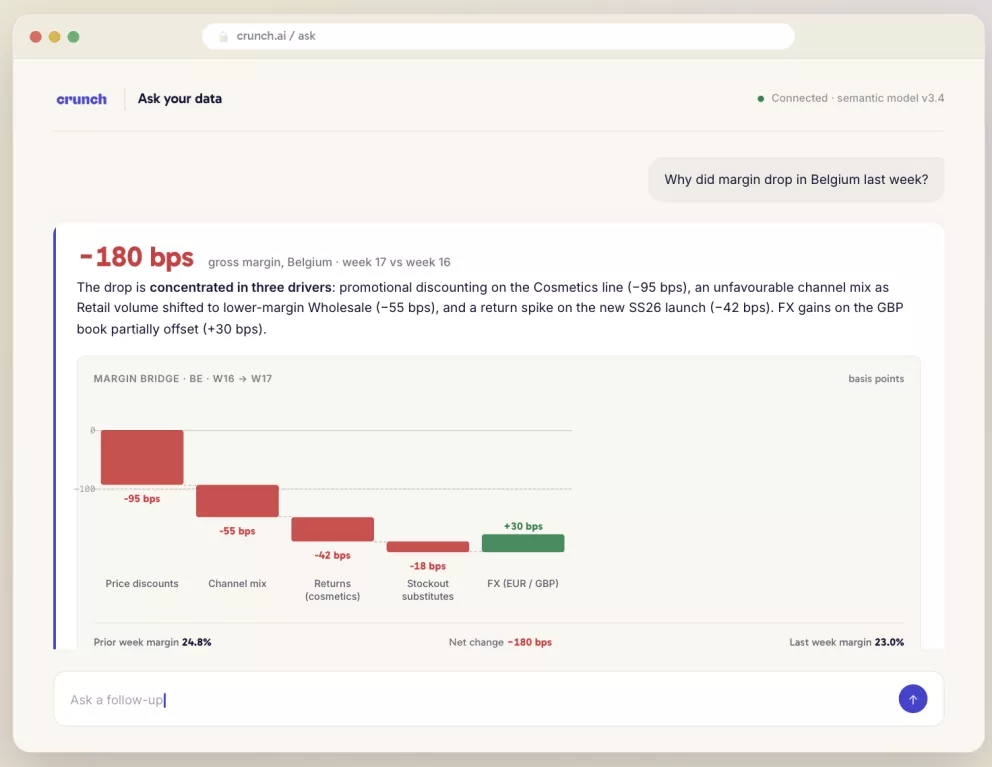
| "Waarom is onze marge in België vorige week gedaald?" | Conversational BI |
| "Vergelijk deze twee campagnes op ROI en klantoverlap" | Conversational BI |
| "Welke SKU's lopen deze week stockout-risico?" | Conversational BI (proactief) |
| "Vat dit dashboard van 14 tegels samen voor de exec call morgen" | Conversational BI |
De vuistregel: draait het elke maandagochtend, dan hoort het in een dashboard. Komt het één keer langs en moet er snel een antwoord komen, dan hoort het in een chat.
Hoe het er in de praktijk uitziet
Ad-hoc analyse wordt eenvoudig
Een triviale vraag is een slechte use case. "Wat was vorige maand het bestverkochte product?" Doe geen moeite. Je bestaande rapport toont dat al.
Waar het wel schittert, is bij die rommelige ad-hoc-vraag die vroeger een week duurde. Iets in de aard van:
"Neem klant A en klant B. Analyseer de overlap in hun productportfolio. Kwantificeer dat in omzet, brutomarge en totaal volume in kubieke meter. Ik wil zien of het zin heeft om hen samen te bedienen."
Dat is een echte vraag. Een nuttige vraag. Het soort dat een category manager op een dinsdagnamiddag gewoon heeft. In de oude wereld mailde je een analist, wachtte je drie dagen, kreeg je een half antwoord, stelde je een vervolgvraag, en wachtte je opnieuw. Tegen vrijdag was de draad verloren.
In de nieuwe wereld typ je het in de chat. Je krijgt een gestructureerd antwoord met de cijfers, de aannames en een grafiek. Je stelt de volgende vraag. Beslissing genomen voor de lunch.
Hoe mensen anders gaan werken
Conversational BI democratiseert data. De marginale kost van een nieuwe vraag valt richting nul. De technische drempel valt weg. Categorymanagers, ops leads, planners: ze worden voor 80% van hun vragen hun eigen analist.
Dat is een structurele shift, geen feature-update.
Bedrijven die dit goed aanpakken, gaan hun concurrenten voorbij in beslissingssnelheid. Niet omdat ze meer data hebben. Omdat ze ze ook effectief gebruiken. Bedrijven die dit niet doen, blijven dashboards bouwen die niemand opent terwijl hun analystenteam verzuipt in tickets.
De technologie ligt klaar. De infrastructuur is de bottleneck. De mentaliteit is de multiplier.

Een eerlijke balans, beide kanten op.
Waar het vandaag werkt, en waar het nog spaak loopt
Waar het vandaag werkt:
- Governed KPI Q&A. "Netto-omzet vorige week per regio." "Marge per categorie t.o.v. vorige maand." Als je metrics goed gedefinieerd zijn, zijn de antwoorden betrouwbaar.
- Dashboards samenvatten. De AI leest je bestaand rapport en legt uit wat er veranderd is en waarom. Handig voor leidinggevenden die om 7 uur 's ochtends geen tijd hebben om een dashboard met 14 tegels te ontleden.
- Begeleide exploratie. De vervolgvragen. "Waarom is dat gebeurd?" "Splits het op naar klantsegment." "Toon enkel de winkels onder 80% sell-through."
- Productiviteit voor analisten. DAX schrijven, SQL, semantische modellen documenteren, drafts van rapporten. De saaie 30% van de week van een analist begint te verdwijnen.
- Operationeel uitzonderingsbeheer. Stockout-risico. Churn-signalen. Late leveringen. Margelekken. Forecast-afwijkingen. Minder chatbot, meer waarschuwingssysteem.
Waar het nog spaak loopt:
- Dubbelzinnige bedrijfstaal. "Verkoop", "actieve klant", "marge", "beschikbare voorraad". Elk departement definieert die anders. Zonder semantisch model gokt de AI. En dat doet hij overtuigend.
- Slechte data wordt gevaarlijk. Een rommelig dashboard ziet er minstens verdacht uit. Een vlot geschreven AI-uitleg laat slechte data autoritair klinken. Dat is een reëel risico.
- Causale redenering. "Waarom is de marge gedaald?" kan te maken hebben met prijs, mix, kosten, retours, kanaal, klantenkortingen, stockouts, FX. Conversational BI kan de data tonen. Het lost het causale probleem niet automatisch op. Daar heb je nog altijd analisten en oordeel voor nodig.
- Gevoelige data. De chatinterface lekt data sneller dan je denkt als row-level security niet strak staat. Hoe groter je gebruikersgroep, hoe lastiger.
- Vertrouwen. Eén of twee foute antwoorden, en de adoptie crasht. Conversational BI heeft traceerbaarheid, bronvermelding en zichtbare logica nodig. Niet enkel een zelfverzekerd klinkend antwoord.
De eerlijke samenvatting: klaar voor governed KPI Q&A en uitzonderingsbeheer. Nog niet klaar om je senior analisten te vervangen op complexe diagnostiek.
Hoe beginnen?
Grote bedrijven gebruiken dit nu al om kosten te reduceren
Dit is het deel waar BI-vendors liever niet hardop over praten. Grote ondernemingen rollen conversational BI uit om werk te absorberen dat vroeger door centrale BI-teams liep. Routinequery's. Ad-hocrapporten. "Kun je dit per regio uitsplitsen?" Een aanzienlijk deel daarvan heeft geen menselijke analist meer nodig. Minder rapportbouwers. Kleinere BI-teams. Een duidelijkere lijn tussen strategisch datawerk (nog altijd zeer menselijk) en operationele rapportering (steeds meer self-service).
Voor mid-market bedrijven ligt de rekensom anders, maar de richting is dezelfde. Je gaat je team waarschijnlijk niet kleiner maken. Je gaat er meer uithalen. De BI-developer die drie dagen per week bezig was met eenmalige rapporten krijgt die drie dagen terug voor het werk dat de business écht vooruithelpt. Daar zit de échte ROI.
Wat je nodig hebt om het te laten werken: de semantische laag
Hier struikelen de meeste projecten. Je kan ChatGPT niet zomaar bovenop Power BI plakken en denken dat het werkt. De AI kent jouw bedrijf niet. Hij weet niet dat "klant" iets anders betekent in finance dan in supply chain. Hij weet niet dat jouw boekjaar in april start. Hij weet niet welk van je drie "omzet"-kolommen de juiste is.
Wat hij nodig heeft, is een semantisch model. Een heldere, governed kaart van je data: welke tabel bevat wat, welke metric betekent wat, welke dimensies kun je netjes joinen, welke beveiligingsregels gelden waar. Zie het als een kookboek voor je business.
Elke grote BI-vendor bouwt deze laag nu in. Power BI semantic models. Looker's modeling layer (LookML). Tableau's published data sources. De data models in Databricks Genie. ThoughtSpot worksheets. Telkens dezelfde poging om de AI een stabiele, leesbare basis te geven om mee te redeneren.
Bouw je breder dan één BI-tool, dan heb je een aparte semantische laag nodig. dbt Semantic Layer. Cube. AtScale. MetricFlow. Daarmee definieer je je metrics één keer en serveer je ze aan BI, AI en ingebedde analytics zonder alles telkens opnieuw te bouwen. Eén bron van waarheid, meerdere consumptielagen.
Zonder die laag gokt de AI. En als generative AI gokt, doet hij dat overtuigend. Gehallucineerde cijfers, met volle borst gepresenteerd, in een boardvergadering. Dat is het horrorscenario.
Eerst je gereedschap scherpen, dan zagen. De technologie ligt klaar. De meeste bedrijven hebben het werk eronder gewoon nog niet gedaan.
De discipline die de meeste projecten overslaan: een evaluatiekader
Conversational BI is software, geen demo. Je moet het testen als software.
Een echt evaluatieset ziet er zo uit: 50 tot 200 representatieve bedrijfsvragen, met verwachte antwoorden, aanvaardbare toleranties, randgevallen, ambigue formuleringen, permission-tests en hallucinatievallen. Je draait die set telkens je het semantisch model wijzigt, het onderliggende taalmodel verandert of nieuwe data toevoegt. Je meet:
- Correctheid. Klopt het cijfer?
- Interpretatie. Klopt de uitleg bij het cijfer?
- Metric-keuze. Heeft hij de juiste KPI uit de catalogus gekozen?
- Filter-interpretatie. Snapt hij de tijdsperiode, regio, segment?
- Beveiliging. Respecteert hij row-level permissions?
- Robuustheid. Verandert het antwoord als je de vraag herformuleert?
- Latency. Snel genoeg om er écht beslissingen op te nemen?
De meeste bedrijven slaan dit volledig over. Ze draaien een happy-path demo, verklaren het project geslaagd, rollen het uit, en zien het vertrouwen verdampen zodra het systeem de eerste keer een fout cijfer aan een directielid presenteert in een meeting.
Wees niet dat bedrijf. Bouw je testset voor je je chatinterface bouwt. En haal die vragen bij je business users, niet uit de fantasie van je datateam.